5 Nextflow
Modules and how to re-use the code
A great advantage of the new DSL2 is to allow the modularization of the code. In particular, you can move a named workflow within a module and keep it aside for being accessed by different pipelines.
The test4 folder provides an example of using modules.
#!/usr/bin/env nextflow
/*
* This code enables the new dsl of Nextflow.
*/
nextflow.enable.dsl=2
/*
* NextFlow test pipe
* @authors
* Luca Cozzuto <lucacozzuto@gmail.com>
*
*/
/*
* Input parameters: read pairs
* Params are stored in the params.config file
*/
version = "1.0"
// this prevents a warning of undefined parameter
params.help = false
// this prints the input parameters
log.info """
BIOCORE@CRG - N F TESTPIPE ~ version ${version}
=============================================
reads : ${params.reads}
"""
// this prints the help in case you use --help parameter in the command line and it stops the pipeline
if (params.help) {
log.info 'This is the Biocore\'s NF test pipeline'
log.info 'Enjoy!'
log.info '\n'
exit 1
}
/*
* Defining the output folders.
*/
fastqcOutputFolder = "ouptut_fastqc"
multiqcOutputFolder = "ouptut_multiQC"
Channel
.fromPath( params.reads ) // read the files indicated by the wildcard
.ifEmpty { error "Cannot find any reads matching: ${params.reads}" } // if empty, complains
.set {reads_for_fastqc} // make the channel "reads_for_fastqc"
include { multiqc } from "${baseDir}/modules/multiqc" addParams(OUTPUT: multiqcOutputFolder)
include { fastqc } from "${baseDir}/modules/fastqc" addParams(OUTPUT: fastqcOutputFolder, LABEL:"twocpus")
workflow {
fastqc_out = fastqc(reads_for_fastqc)
multiqc(fastqc_out.collect())
}
workflow.onComplete {
println ( workflow.success ? "\nDone! Open the following report in your browser --> ${multiqcOutputFolder}/multiqc_report.html\n" : "Oops .. something went wrong" )
}
We now include two modules, named fastqc and multiqc, from `${baseDir}/modules/fastqc.nf` and `${baseDir}/modules/multiqc.nf`.
Let’s inspect the multiQC module:
/*
* multiqc module
*/
params.CONTAINER = "quay.io/biocontainers/multiqc:1.9--pyh9f0ad1d_0"
params.OUTPUT = "multiqc_output"
process multiqc {
publishDir(params.OUTPUT, mode: 'copy')
container params.CONTAINER
input:
path (inputfiles)
output:
path "multiqc_report.html"
script:
"""
multiqc .
"""
}
The module multiqc takes as input a channel with files containing reads and produces as output the files generated by the multiqc program.
The module contains the directive publishDir, the tag, and the container to be used and has a similar input, output, and script session as the fastqc process in test3.nf.
A module can contain its own parameters that can be used for connecting the main script to some variables inside the module.
In this example, we have the declaration of two parameters that are defined at the beginning:
/*
* fastqc module
*/
params.CONTAINER = "quay.io/biocontainers/fastqc:0.11.9--0"
params.OUTPUT = "fastqc_output"
params.LABEL = ""
process fastqc {
publishDir(params.OUTPUT, mode: 'copy')
tag { "${reads}" }
container params.CONTAINER
label (params.LABEL)
input:
path(reads)
output:
path("*_fastqc*")
script:
"""
fastqc -t ${task.cpus} ${reads}
"""
}
They can be overridden from the main script that is calling the module:
The parameter params.OUTPUT can be used for connecting the output of this module with the one in the main script.
The parameter params.CONTAINER can be used for declaring the image to use for this particular module.
In this example, in our main script, we pass only the OUTPUT parameters by writing them as follows:
#!/usr/bin/env nextflow
/*
* This code enables the new dsl of Nextflow.
*/
nextflow.enable.dsl=2
/*
* NextFlow test pipe
* @authors
* Luca Cozzuto <lucacozzuto@gmail.com>
*
*/
/*
* Input parameters: read pairs
* Params are stored in the params.config file
*/
version = "1.0"
// this prevents a warning of undefined parameter
params.help = false
// this prints the input parameters
log.info """
BIOCORE@CRG - N F TESTPIPE ~ version ${version}
=============================================
reads : ${params.reads}
"""
// this prints the help in case you use --help parameter in the command line and it stops the pipeline
if (params.help) {
log.info 'This is the Biocore\'s NF test pipeline'
log.info 'Enjoy!'
log.info '\n'
exit 1
}
/*
* Defining the output folders.
*/
fastqcOutputFolder = "ouptut_fastqc"
multiqcOutputFolder = "ouptut_multiQC"
Channel
.fromPath( params.reads ) // read the files indicated by the wildcard
.ifEmpty { error "Cannot find any reads matching: ${params.reads}" } // if empty, complains
.set {reads_for_fastqc} // make the channel "reads_for_fastqc"
include { multiqc } from "${baseDir}/modules/multiqc" addParams(OUTPUT: multiqcOutputFolder)
include { fastqc } from "${baseDir}/modules/fastqc" addParams(OUTPUT: fastqcOutputFolder, LABEL:"twocpus")
workflow {
fastqc_out = fastqc(reads_for_fastqc)
multiqc(fastqc_out.collect())
}
workflow.onComplete {
println ( workflow.success ? "\nDone! Open the following report in your browser --> ${multiqcOutputFolder}/multiqc_report.html\n" : "Oops .. something went wrong" )
}
While we keep the information of the container inside the module for better reproducibility:
/*
* multiqc module
*/
params.CONTAINER = "quay.io/biocontainers/multiqc:1.9--pyh9f0ad1d_0"
params.OUTPUT = "multiqc_output"
process multiqc {
publishDir(params.OUTPUT, mode: 'copy')
container params.CONTAINER
input:
path (inputfiles)
output:
path "multiqc_report.html"
script:
"""
multiqc .
"""
}
Here you see that we are not using our own image, but rather we use the image provided by biocontainers in quay.
Let’s have a look at the fastqc.nf module:
/*
* fastqc module
*/
params.CONTAINER = "quay.io/biocontainers/fastqc:0.11.9--0"
params.OUTPUT = "fastqc_output"
params.LABEL = ""
process fastqc {
publishDir(params.OUTPUT, mode: 'copy')
tag { "${reads}" }
container params.CONTAINER
label (params.LABEL)
input:
path(reads)
output:
path("*_fastqc*")
script:
"""
fastqc -t ${task.cpus} ${reads}
"""
}
It is very similar to the multiqc one: we just add an extra parameter for connecting the resources defined in the nextflow.config file and the label indicated in the process. Also in the script part, there is a connection between the fastqc command line and the number of threads defined in the nextflow config file.
To use this module, we have to change the main code as follows:
#!/usr/bin/env nextflow
/*
* This code enables the new dsl of Nextflow.
*/
nextflow.enable.dsl=2
/*
* NextFlow test pipe
* @authors
* Luca Cozzuto <lucacozzuto@gmail.com>
*
*/
/*
* Input parameters: read pairs
* Params are stored in the params.config file
*/
version = "1.0"
// this prevents a warning of undefined parameter
params.help = false
// this prints the input parameters
log.info """
BIOCORE@CRG - N F TESTPIPE ~ version ${version}
=============================================
reads : ${params.reads}
"""
// this prints the help in case you use --help parameter in the command line and it stops the pipeline
if (params.help) {
log.info 'This is the Biocore\'s NF test pipeline'
log.info 'Enjoy!'
log.info '\n'
exit 1
}
/*
* Defining the output folders.
*/
fastqcOutputFolder = "ouptut_fastqc"
multiqcOutputFolder = "ouptut_multiQC"
Channel
.fromPath( params.reads ) // read the files indicated by the wildcard
.ifEmpty { error "Cannot find any reads matching: ${params.reads}" } // if empty, complains
.set {reads_for_fastqc} // make the channel "reads_for_fastqc"
include { multiqc } from "${baseDir}/modules/multiqc" addParams(OUTPUT: multiqcOutputFolder)
include { fastqc } from "${baseDir}/modules/fastqc" addParams(OUTPUT: fastqcOutputFolder, LABEL:"twocpus")
workflow {
fastqc_out = fastqc(reads_for_fastqc)
multiqc(fastqc_out.collect())
}
workflow.onComplete {
println ( workflow.success ? "\nDone! Open the following report in your browser --> ${multiqcOutputFolder}/multiqc_report.html\n" : "Oops .. something went wrong" )
}
The label twocpus is specified in the nextflow.config file for each profile:
Note
IMPORTANT: You have to specify a default image to run nextflow -with-docker or -with-singularity and you have to have a container(s) defined inside modules.
EXERCISE
Make a module wrapper for the bowtie tool and change the script in test3 accordingly.
Solution
Solution in the folder test5
Reporting and graphical interface
Nextflow has an embedded function for reporting information about the resources requested for each job and the timing; to generate a html report, run Nextflow with the -with-report parameter :
nextflow run test5.nf -with-docker -bg -with-report > log
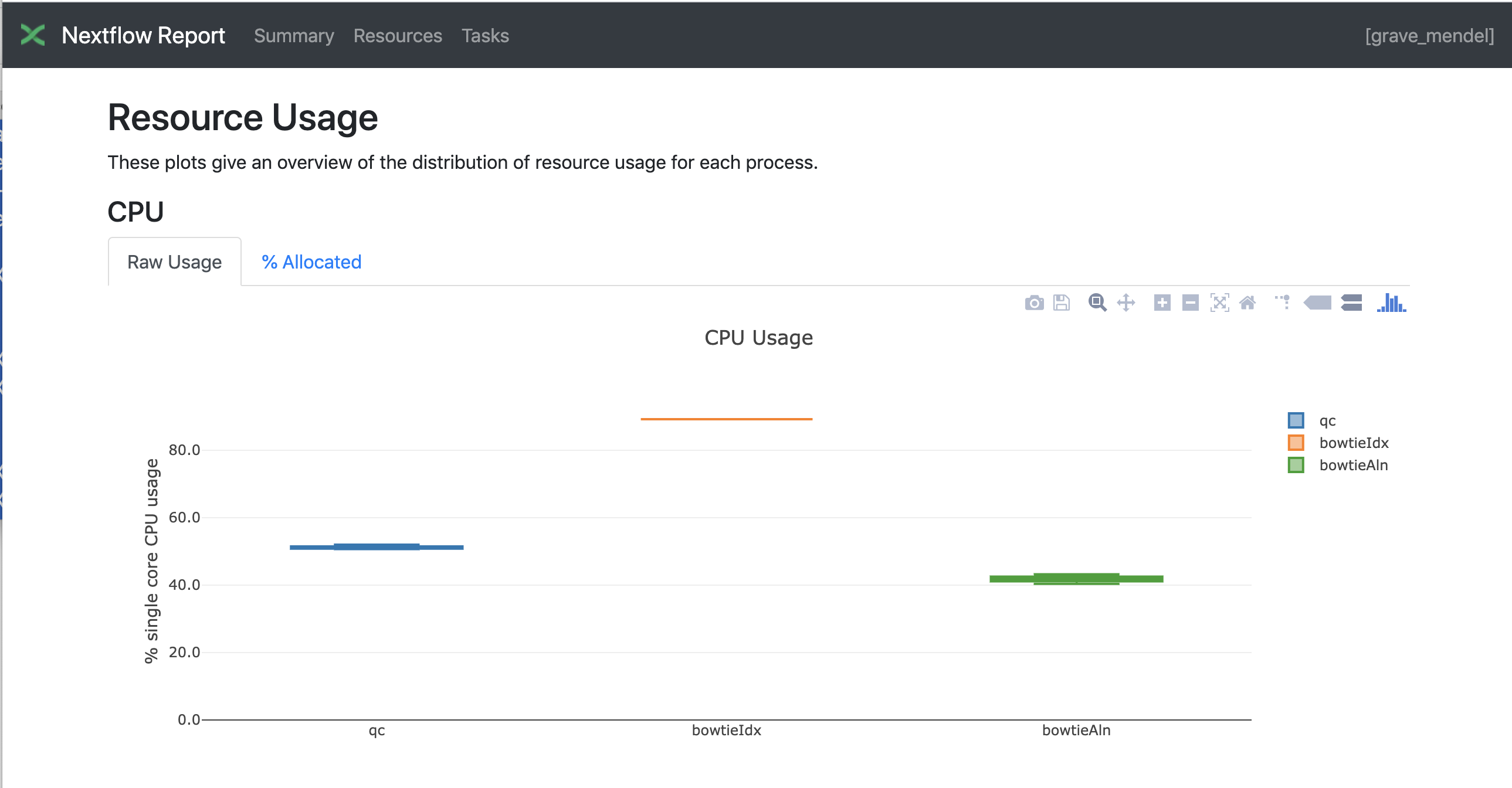
Nextflow Tower is an open-source monitoring and managing platform for Nextflow workflows. There are two versions:
Open source for monitoring of single pipelines.
Commercial one for workflow management, monitoring, and resource optimization.
We will show the open-source one.
First, you need to access the tower.nf website and login.

We recommend using either Google or GitHub for login. The email has to be accepted manually by the tower team.
Once you are signed in you will see a page like this:
You can generate your token at https://tower.nf/tokens and copy-paste it into your pipeline using this snippet in the configuration file:
tower {
accessToken = '<YOUR TOKEN>'
enabled = true
}
or exporting those environmental variables:
export TOWER_ACCESS_TOKEN=*******YOUR***TOKEN*****HERE*******
Now we can launch the pipeline:
nextflow run test5.nf -with-singularity -with-tower -bg > log
CAPSULE: Downloading dependency io.nextflow:nf-tower:jar:20.09.1-edge
CAPSULE: Downloading dependency org.codehaus.groovy:groovy-nio:jar:3.0.5
CAPSULE: Downloading dependency io.nextflow:nextflow:jar:20.09.1-edge
CAPSULE: Downloading dependency io.nextflow:nf-httpfs:jar:20.09.1-edge
CAPSULE: Downloading dependency org.codehaus.groovy:groovy-json:jar:3.0.5
CAPSULE: Downloading dependency org.codehaus.groovy:groovy:jar:3.0.5
CAPSULE: Downloading dependency io.nextflow:nf-amazon:jar:20.09.1-edge
CAPSULE: Downloading dependency org.codehaus.groovy:groovy-templates:jar:3.0.5
CAPSULE: Downloading dependency org.codehaus.groovy:groovy-xml:jar:3.0.5
and go to the tower website again:
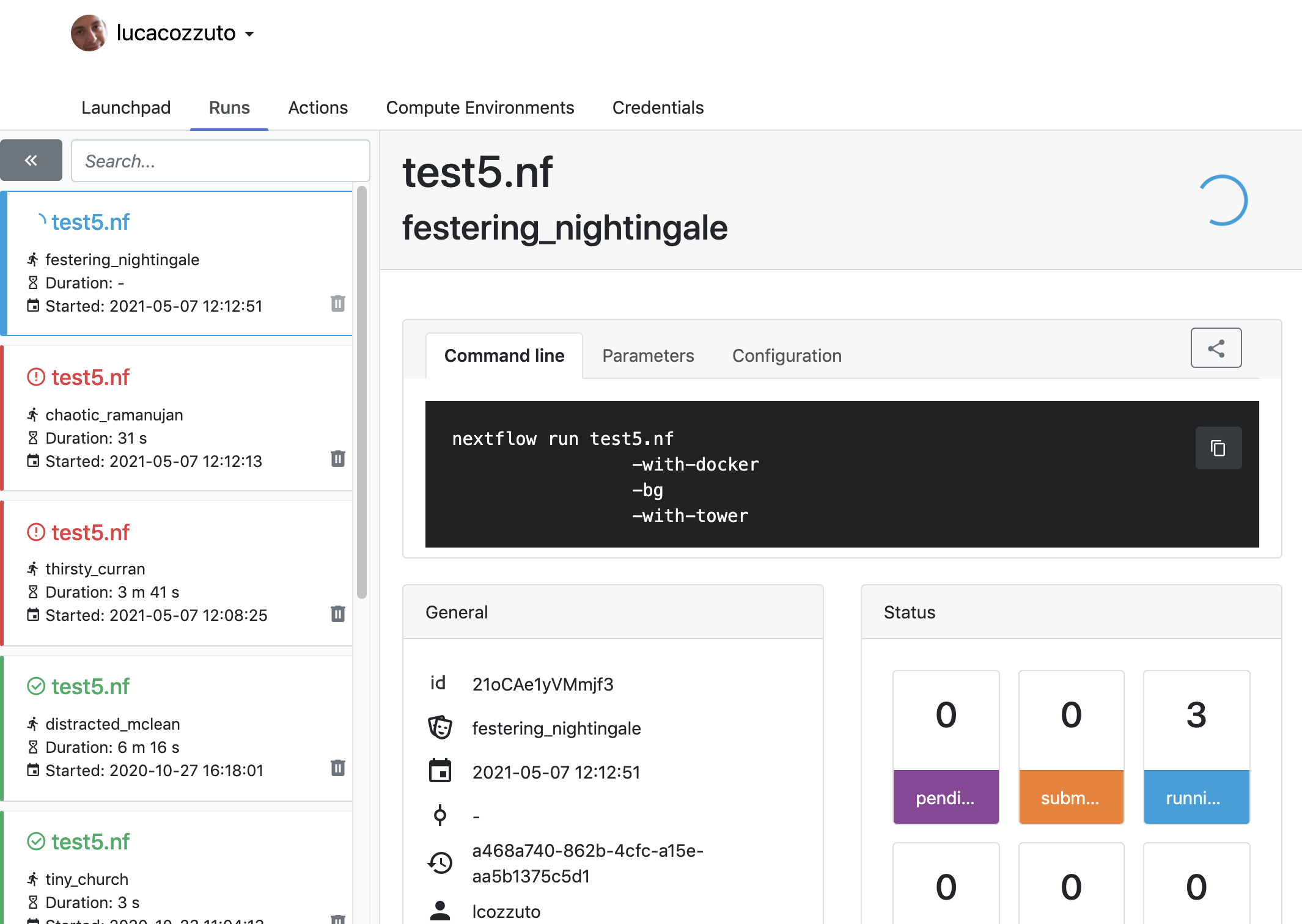
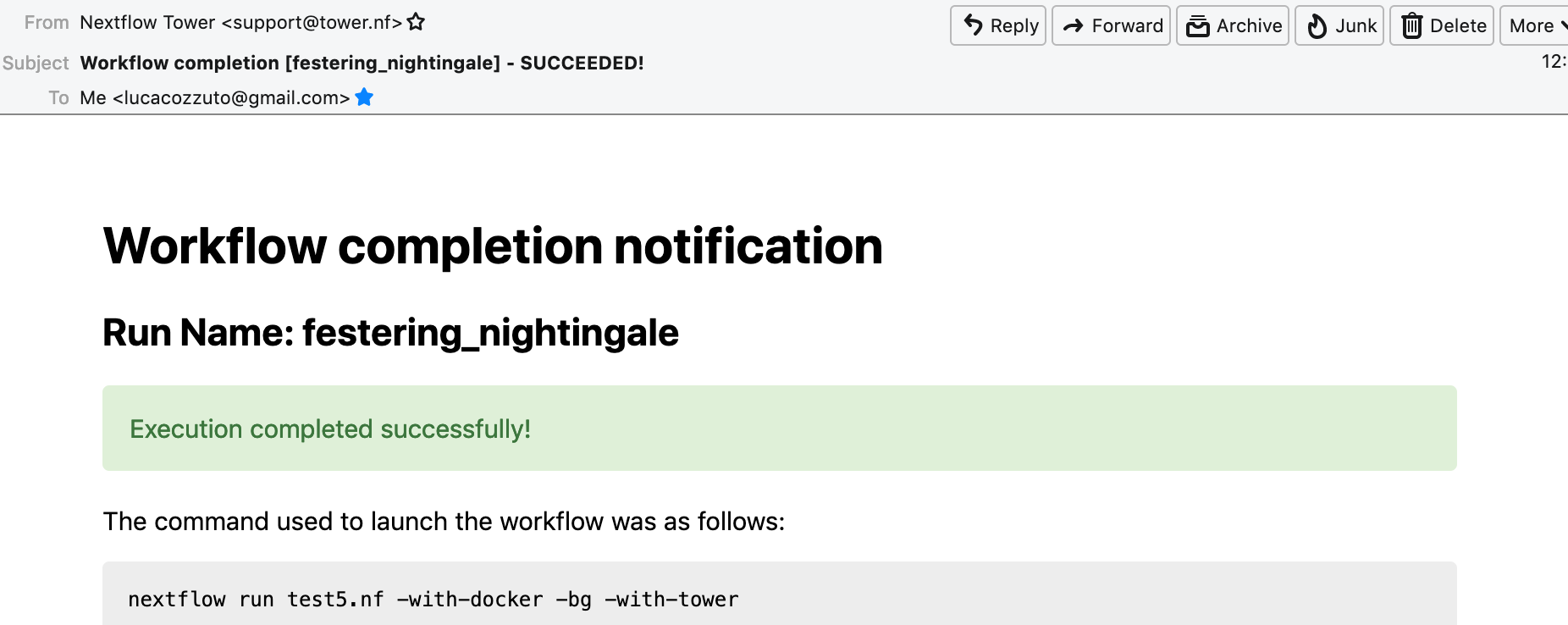
When the pipeline is finished we can also receive a mail.