5.1 Introduction
5.1.1 What is Nextflow?
Nextflow is a domain specific language for workflow orchestration that stems from Groovy. It enables scalable and reproducible workflows using software containers.
It was developed at the CRG in the Lab of Cedric Notredame by Paolo Di Tommaso https://github.com/pditommaso.
The Nextflow documentation is available here and you can ask help to the community using their gitter channel
Nextflow has been upgraded in 2020 from DSL1 (Domain-Specific Language) version to DSL2. In this course we will use exclusively DSL2.
5.1.2 What is Nextflow for?
It is for making pipelines without caring about parallelization, dependencies, intermediate file names, data structures, handling exceptions, resuming executions etc.
It was published in Nature Biotechnology in 2017.

There is a growing number of publications mentioning Nextflow in PubMed, since many bioinformaticians are starting to write their pipeline with Nextflow.
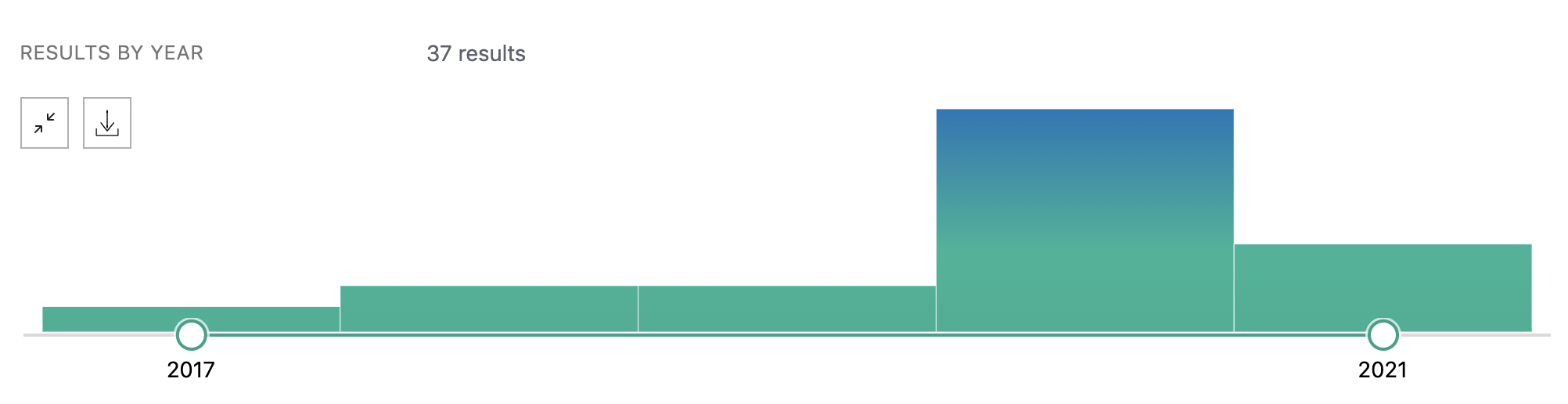
Here is a curated list of Nextflow pipelines.
And here is a group of pipelines written in a collaborative way from the NF-core project.
Some pipelines written in Nextflow are used for SARS-Cov-2 analysis, for example:
- the artic Network pipeline: ncov2019-artic-nf.
- the CRG / EGA viral Beacon pipeline: Master of Pores.
- the nf-core pipeline: viralrecon.
5.1.3 Main advantages
- Fast prototyping
You can quickly write a small pipeline that can be expanded incrementally.
Each task is independent and can be easily added to other ones.
You can reuse your scripts and tools without rewriting / adapting them.
- Reproducibility
Nextflow supports Docker and Singularity containers technology. Their use will make the pipelines reproducible in any Unix environment.
Nextflow is integrated with GitHub code sharing platform, so you can call directly a specific version of pipeline from a repository, download it and use it on the fly.
- Portability
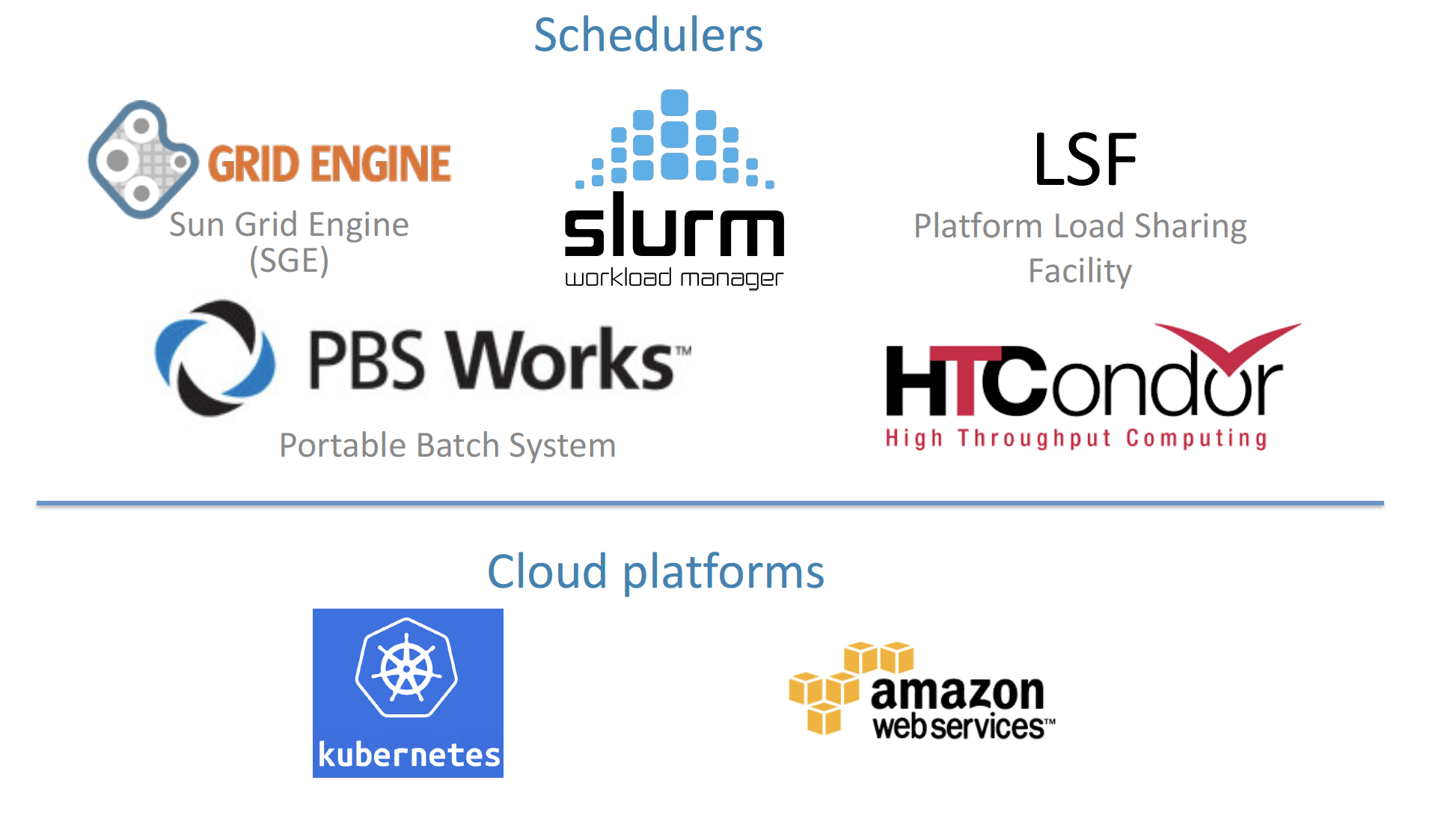
Nextflow can be executed on multiple platforms without modifiying the code. It supports several schedulers such as SGE, LSF, SLURM, PBS and HTCondor and cloud platforms like Kubernetes, Amazon AWS and Google Cloud.
- Scalability
Nextflow is based on the dataflow programming model which simplifies writing complex pipelines.
The tool takes care of parallelizing the processes without additional written code.
The resulting applications are inherently parallel and can scale-up or scale-out, transparently, without having to adapt to a specific platform architecture.
- Resumable, thanks to continuous checkpoints
All the intermediate results produced during the pipeline execution are automatically tracked.
For each process a temporary folder is created and is cached (or not) once resuming an execution.