

Protein-DNA interactions
Different class of proteins are known to bind nucleic acids thanks to some domains that have affinities for single or double stranded DNA or RNA. The proteins that bind DNA can be classified into:
- Non-specific DNA-binding proteins, such as histones, polymerases and helicases.
- Specific DNA-binding proteins, such as transcription factors.
Specific DNA sequences bound by a protein can be identified using the following experiments:
- EMSA (electrophoretic mobility shift assay, or gel shift assay). It is a common affinity electrophores technique used to study protein–DNA or protein–RNA interactions. This procedure can determine if a protein or mixture of proteins is capable of binding to a given DNA or RNA sequence, and can sometimes indicate if more than one protein molecule is involved in the binding complex.
- DNA pull-down assay. Pull-down assays are used to selectively extract a protein–DNA complex from a sample. Typically, the pull-down assay uses a DNA probe labeled with a high affinity tag, such as biotin, which allows the probe to be recovered or immobilized. A biotinylated DNA probe can be complexed with a protein from a cell lysate in a reaction similar to that used in the EMSA and then used to purify the complex using agarose or magnetic beads. The proteins are then eluted from the DNA and detected by western blot or identified by mass spectrometry.
- SELEX. It is stands for Systematic Evolution of Ligands by EXponential Enrichment. SELEX is an experimental procedure that involves the progressive selection, from a large combinatorial double-stranded oligonucleotide library, of proteins with variable DNA-binding affinities and specificities by repeated rounds of partition and amplification.
- ChIP-on-chip. The complex protein DNA is fixed using crosslinking and then pulled down using an antibody specific for the protein. The crosslink is then reverted and the bound sequences hybridized on a microarray chip to discover the bound genes.
- ChIP-Seq. Similar to the ChIP-on-chip but it is a direct sequencing of the DNA captured by the immunoprecipitated protein.
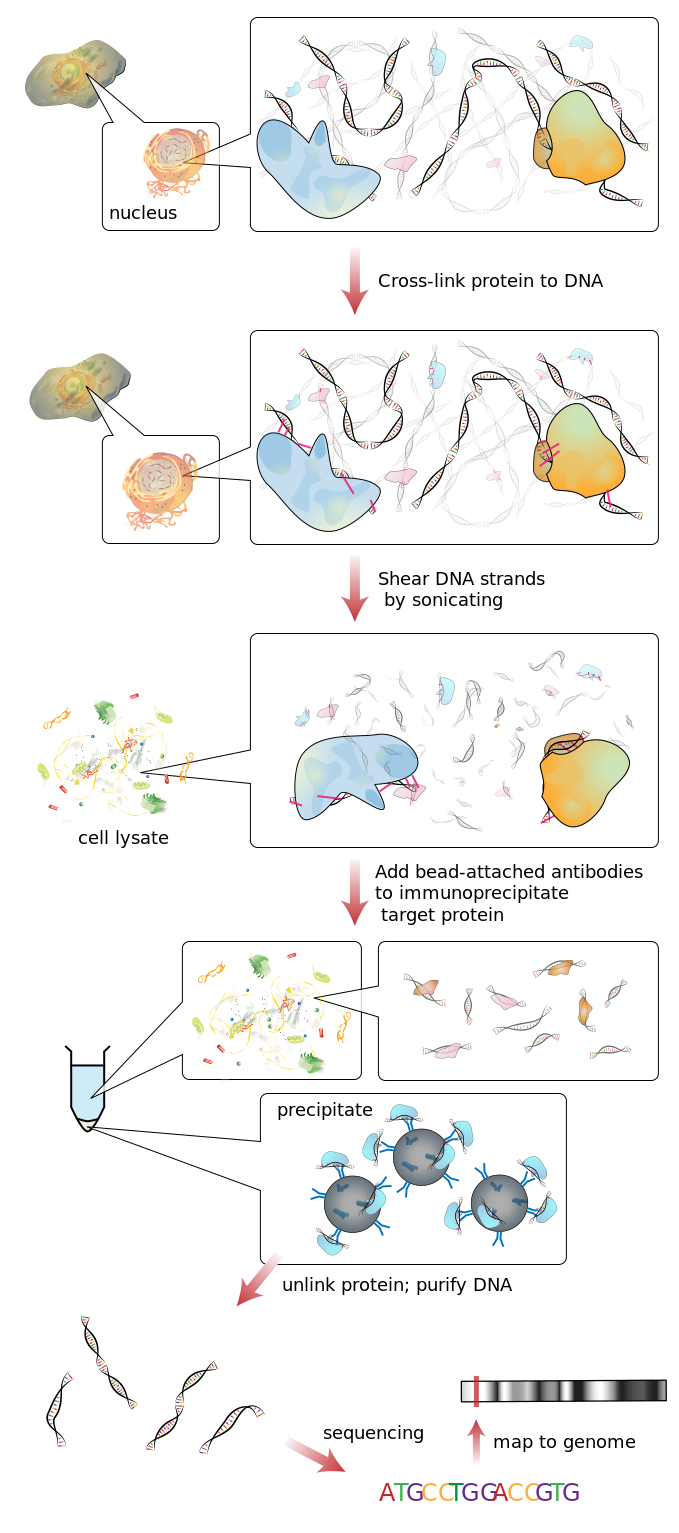
ChIP-Seq workflow
Frow wikipedia:
ChIP-Seq data repositories
Raw sequencing data and results from ChIPseq experiments generally have to be uploaded to public repositories for supporting scientific publications. The two mostly used repositories:
- Gene Expression Omnibus (GEO) from NCBI
- ArrayExpress from EMBL/EBI
Until 2016 these two databases were mirroring each other.
GEO
We will focus now on GEO, and this “Series of experiments “GSE41589” in particular.

As you can see, GEO provides information about the study and experiment including the overall design, the sequencing platform used (indicated by identifiers strating with GPL), samples (indicated with the prefix GSM), the BioProject identifier PRJNA177615 and the SRA identifier SRP016121. Finally a list of result files .
- Sequence Read Archive (SRA) collects all the raw sequencing data otgether with information about the sequencign method.
- BioProject is a collection of biological data related to a single initiative, originating from a single organization or from a consortium. A BioProject record provides users a single place to find links to the diverse data types generated for that project.
Exercise:
- Which samples correspond to the ChIP-seq experiment of DNA binding of the Suz12 protein? (look for the input/control samples as well)
The analysis of ChIP-Seq data produces a list of genomic positions (aka, peaks) with some probability/score to be bound to a protein of interest. The higher the number of reads found in that genomic position, together with the a low number of mapped tags in the control, the higher the probability that the binding event is not a false positive one.
Let’s download such a list of the Suz12 protein binding regions which is provided in the file GSE41589_Suz12_BindingSites.txt.gz. This list of peaks is represented in a tabular format called BED format, which is a standard format for the results of any ChIP-Seq data analysis. The BED file has one line per feature (in this case, a peak, or the genome region to which a protein binds), each containing between 3 and 12 columns of data.
The typical 6-field BED format:
| chrom | chromStart | chromEnd | name | score | strand |
|---|---|---|---|---|---|
| chr7 | 127471196 | 127472363 | Pos1 | 0 | + |
| chr7 | 127472363 | 127473530 | Pos2 | 0 | + |
| chr7 | 127473530 | 127474697 | Pos3 | 0 | + |
| chr7 | 127474697 | 127475864 | Pos4 | 0 | + |
Additionally you may have up to another 6 fields:
| thickStart | thickEnd | itemRgb | blockCount | blockSizes | blockStarts |
|---|---|---|---|---|---|
| 127471196 | 127472363 | 255,0,0 | 0 | 0 | 0 |
| 127472363 | 127473530 | 255,0,0 | 0 | 0 | 0 |
| 127473530 | 127474697 | 255,0,0 | 0 | 0 | 0 |
| 127474697 | 127475864 | 255,0,0 | 0 | 0 | 0 |
Exercise:
- How many regions of Suz12 binding were identified on chromosome Y?
- What is the distance between the first and the last peak on chromosome Y?
ENCODE
The Encyclopedia of DNA Elements (ENCODE) Consortium is an ongoing international collaboration aimed at compiling a comprehensive list of functional elements in the human genome.
Let’s have a look at the ENCODE DATA MATRIX. Let’s select this ChIPseq experiment.
Exercise:
- How may biological replicates were used in this experiment?
- What transcription factor was studied?
- Which tissue was used?
- Who was a patient(s)?
- Which sequencing platform was used in this experiment?
We can also explore identified peaks (the BED file) in the embedded into ENCODE webpage the Genome Browser. Click on the tab “Genome Browser” and type in the search box “REST”, click “Submit”.
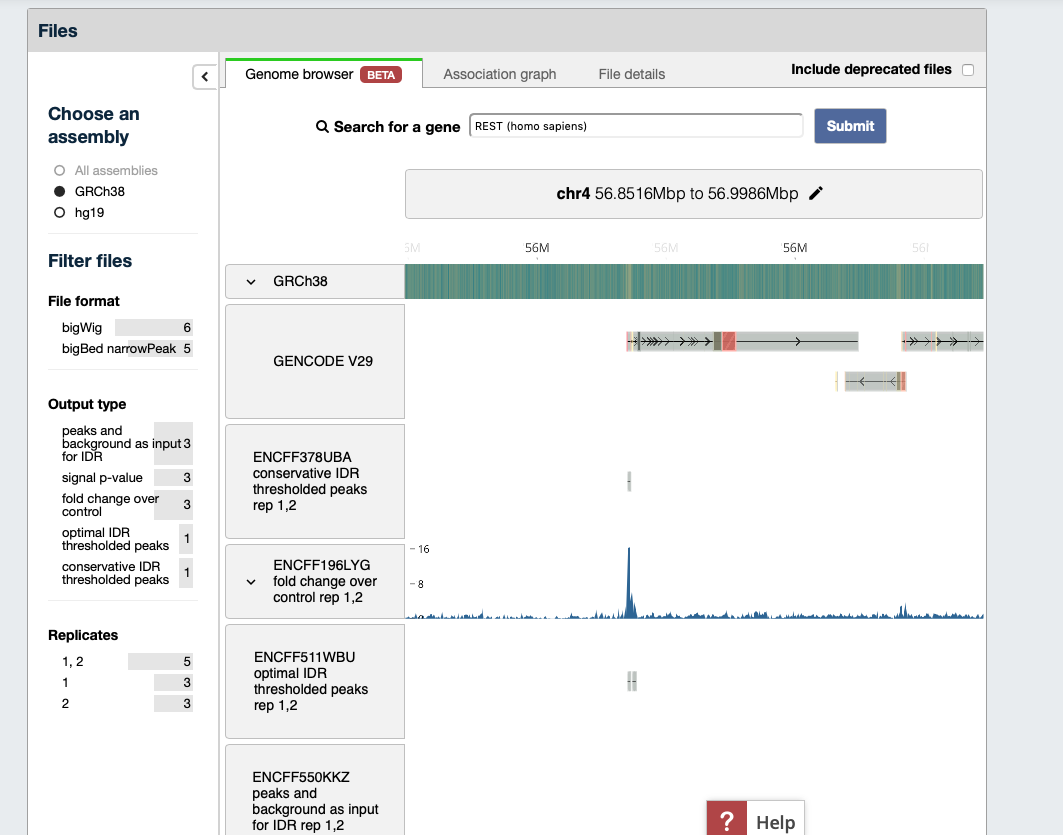
ChIP-Seq experiments in the UCSC Genome Browser
You already became familiar with UCSC Genome Browser in the session Genome sequences and annotations.
Searching for known experiments
Open the UCSC genome browser, select the latest assembly of the human genome, hg38, and click “GO”.
Scroll down to the tracks in the section REGULATION.
And click on the ENCODE link that will bring us at this page:

We can select either clusters or peak. The former will contain information about which cell line the peak is expressed while the second are available only for a given cell line (you have to select a cell line too).
Let’s click on the link “TF clusters”. On the top of the newly appeared page select “Full” for Display Mode and Filter by factor selecting Suz12 in the pulled down list. Click Submit on top of the page to return to the Browser.
Now let’s serach for the Suz12 gene to investigate if it binds to its own promoter. You can see the black box at the position chr17:31916990-31917580. The peak lies in the middle between TSS of the Suz12 gene going in 5’-3’ of one strand and TSS of the UTP6 gene on the other DNA strand; this is known as a bidirectional promoter. Clicking on the peak gives us information about the experiment and peak itself.
| signal | abr | cellType | factor | experiment | lab | more info | |
|---|---|---|---|---|---|---|---|
| 1 | 938.00 | G | GM12878 | SUZ12 | ENCSR091BOQ | bernstein | ENCFF547FUI |
Visualizing your own BED file of ChIP-seq peaks
You can also add your own data to be visualized in the Genome Browser. Let’s move to the mouse genome (version mm9). We can upload the peak list we downloaded previously (the file GSE41589_Suz12_BindingSites.txt.gz) clicking on ADD CUSTOM TRACKS. Upload this file via Upload -> Choose file -> submit. Then, on a new page view in: -> Genome Browser -> go.
NOTE: We recommend always using compressed file for uploading since it will speed up the whole operation and reduce the risk of server time out.
We can search again for Suz12, zoom out to see black boxes on User Track on the top of other tracks. We can see that this peak between two genes is a conserved feature and we got it in our experiment similarly to the ENCODE experiment we visualized before.
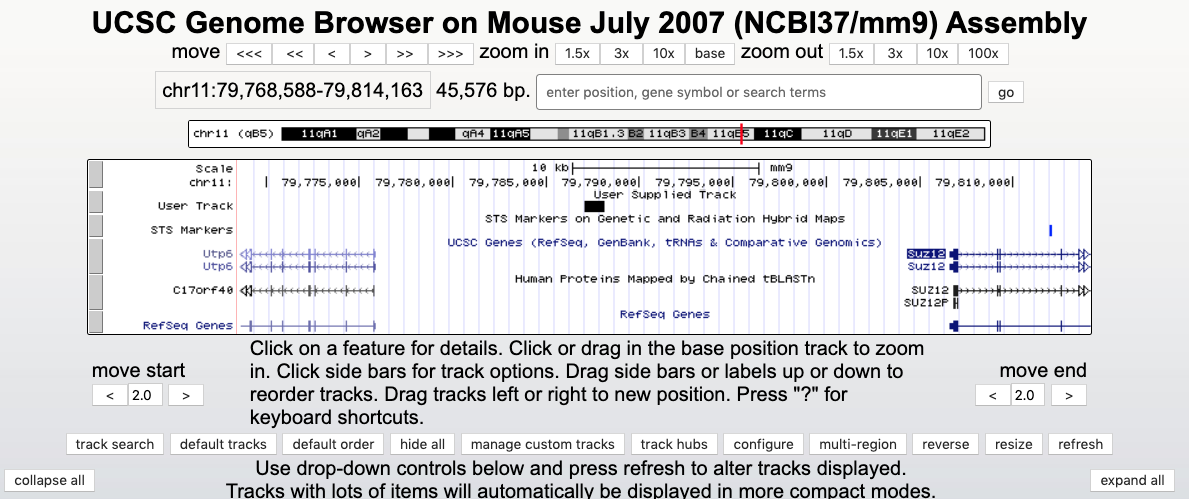
Do not close this window as we will be using it again later!
DNA motifs
Proteins that bind specific regions of DNA have domains that recognize specific stretches of nucleotides that can be represented as motifs or patterns. These motifs are often non-exact and can have some degrees of variability in different positions. They can be represented as “consensus logos” in which a number of stacked nucleotides are placed with a size proportional to their conservation in that position.
 |
| Example pattern recognized by the mouse gene Pou5f1 |
In this example, in positions 3, 4 and 9 there is a conserved thymidine; while in positions 8 and 14, a conserved adenosine; and in 10, a guanine.
The motif can be described also as a matrix in which each base has a probability or a frequency in each position. Here the raw position frequency matrix (PFMs):
>MA0142.1 Pou5f1::Sox2
63.00 579.00 11.00 47.00 118.00 415.00 206.00 1235.00 17.00 10.00 14.00 1050.00 887.00 1200.00 198.00
846.00 58.00 50.00 12.00 363.00 18.00 365.00 30.00 5.00 16.00 1029.00 16.00 68.00 33.00 119.00
66.00 28.00 36.00 79.00 825.00 29.00 186.00 24.00 15.00 1239.00 129.00 30.00 315.00 75.00 207.00
389.00 701.00 1270.00 1231.00 63.00 907.00 612.00 80.00 1332.00 104.00 196.00 269.00 92.00 53.00 837.00
Repositories of known DNA motifs
The DNA motif matrices, logos and other informations are stored in public and private resources, such as:
- JASPAR - open source and free collection of motifs as matrices.
- TRANSFAC - private collection of eukaryotic transcription factors, genomic binding sites and DNA-binding profiles (there is freely available old version).
Let’s search JASPAR for Pou5f1. We cab see that the mouse motif is slightly larger than the human one (at 5’) but they are quite conserved. Let’s click on the human motif MA0792.1.
We can read that the data comes from a ChIP-Seq experiments and the corresponding studies are linked. We see that binding site information is stored as sequence in html or plain text and as coordinates in bed format.
JASPAR has some other interesting features, such as an application to infer the ability of a protein to bind a particular motif. Clicking here http://jaspar.genereg.net/inference you can submit your domain/protein sequence to check if there is a match with a matrix in the Jaspar database.
Or you can display the predicted protein binding within the UCSC gneome browser by clicking here
DNA motif discovery
You can also be interested in discovering novel and known motifs from your own experimental data or to see if in particular conditions there are different motifs. In case of searching for known motifs (that are in databases) you might find a protein that is competing for the same positions as the protein you study or acting in a complex with your protein.
To address these tasks, there is a number of tools, some of which are also availble as online web app, e.g., the MEME suite, which we will use to discover DNA motifs in the Suz12 DNA-binding regions on chromosome 7 of the mouse genome.
For that, we first need to obtain the DNA sequence of our peaks located on chrY. We can do it using the UCSC Genome Browser as follows:
-
Go back to the UCSC Genome Browser window that displays the Custom Track for Suz12 peaks. (If you closed the window do the following: Open the UCSC genome browser. Select “Mouse”. Select the assembly mm9 and click “GO”. Add Custom track by uploading the file GSE41589_Suz12_BindingSites.txt.gz. See it the browser.)
-
On the top panel of the Browser window select TOOL -> TABLE BROWSER as shown below.
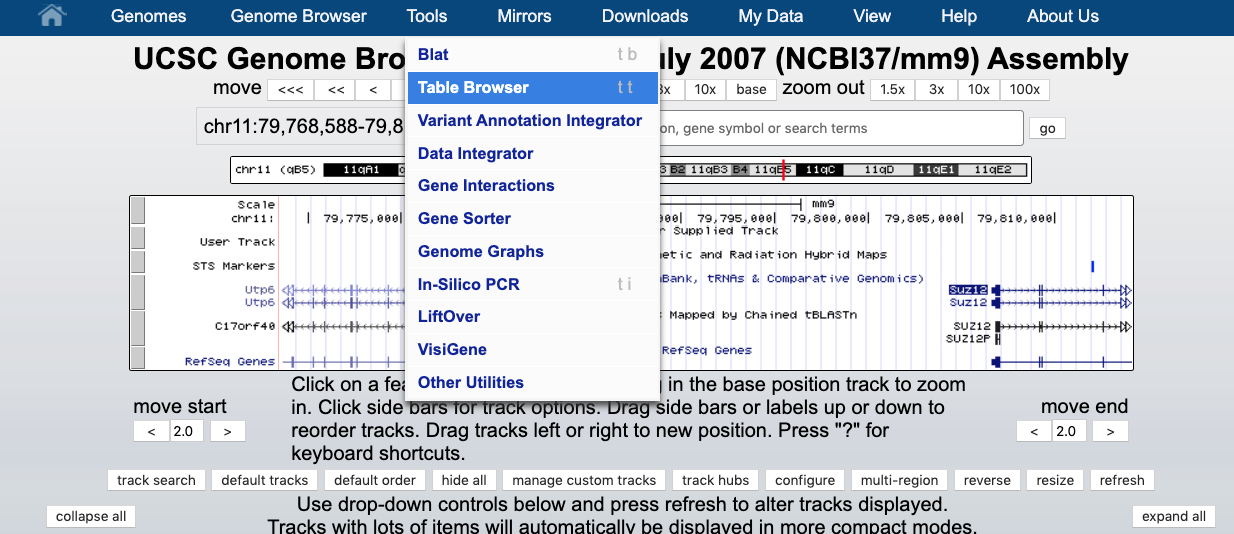
- Choose region -> position: chrY, output format: sequence, define a name in the output file (e.g., mm9_chrY.txt), and select file type returned: gzipped compressed, and click get output, as shown below.
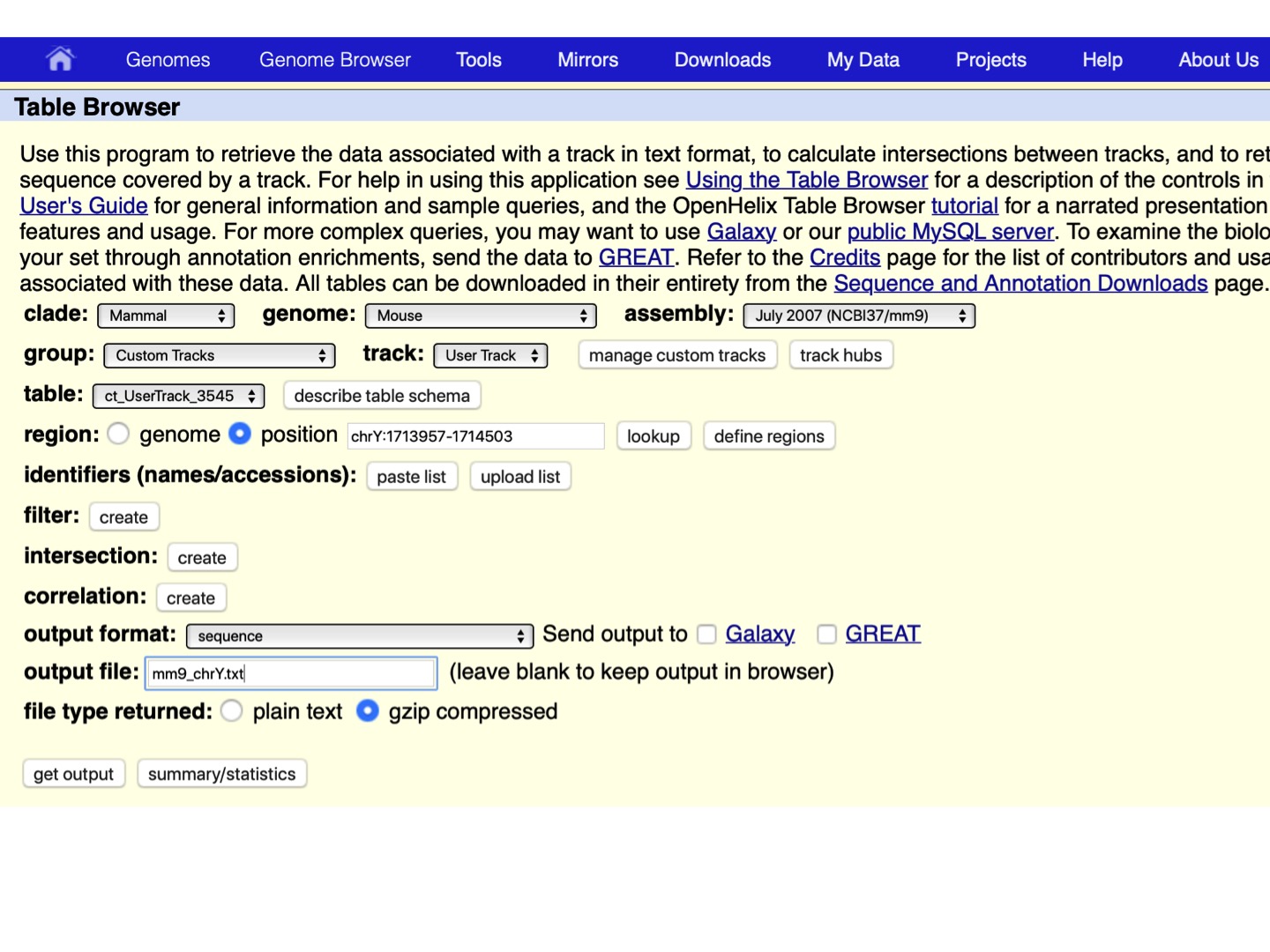 Let’s open the file:
Let’s open the file:
>mm9_ct_UserTrack_3545_0 range=chrY:1713957-1714503 5'pad=0 3'pad=0 strand=+ repeatMasking=none
CAGAATGTGACTCAGGTCATCAGGTCATTTCGGTAGGGAATTAATTTTGG
GTTTCTAGGAGGCCATATGAAAAGGTAAAGCCTAGATGCTGAAAGTTTCT
GAGTCCAACTAGGGAAGGAACCAGCATGAGAGGGGTTCTATGATGTAAGC
TGAACTAGAGTGATGTTACAGAGCACTGGTCAGGGGTTTGCACATCTATT
CCACTTGGAGGCGCTAGAATCCCTTGAAGGTGGGTGGGTACTACTATGTT
TGCAGTAGTGTGTAAAAGCCAGGTCAGCTCCTGAACCACAAAGTTGTTCC
...
We can see that the file contains five sequences, which is the number of peaks on chromosome Y.
We can now go to the MEME program to identify motifs in these peaks. And upload the uncompressed file of downloaded peak sequences, mm9_chrY.txt.

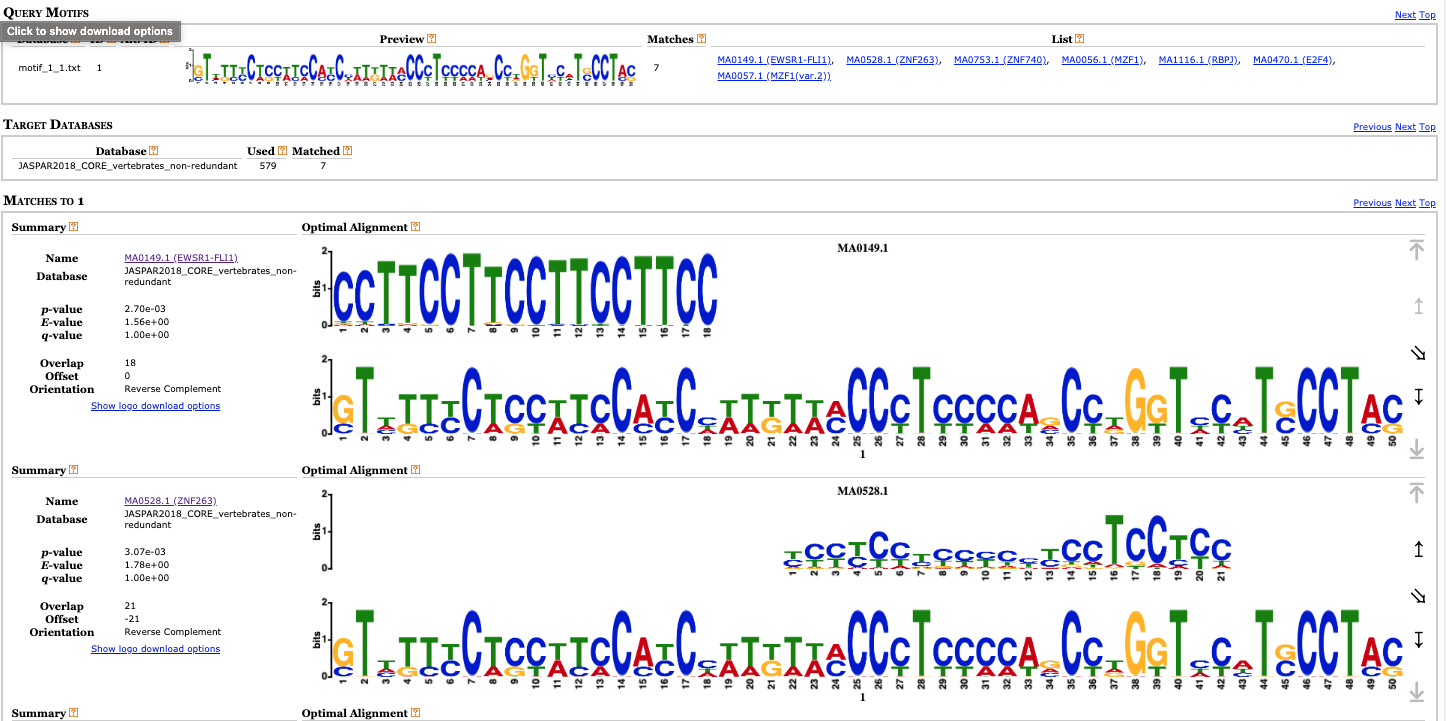
We see that MEME found 3 motifs (as many as were defined in the parameter list). From here we can submit them directly to other programs of the suite or download them in the MEME format and analyze using other programs.
For example, we can use the tool TomTom that allows to compare our motifs with those that can be found in databases, e.g., JASPAR. Upload the motif and use Jaspar NON reduntand -> Jaspar Core 2018 as database. We can see that among different results we got proteins with DNA binding domains called zinc finger domains and it is known that Suz12 is a protein containing zinc finger domain.
Other tools in the MEME suite allow to scan whole genomes for finding positions compatible with the motif matrix and the closest genes (i.e., the ones that are likely under control of that transcription factor).
You can try some of those tools, for example, Fimo that produces a list of positions matched by the motif or T-Gene that predicts regulatory links between genomic loci and genes.