

Biology as information
Bioinformatics: interdisciplinary field that develops methods and software tools for understanding biological data.
Biology + informatics.
Similar or related terms: computational biology, systems biology, etc.
A bit of pre-history
- Schrodinger, What is life? (1944) - Mention to code-script of organism
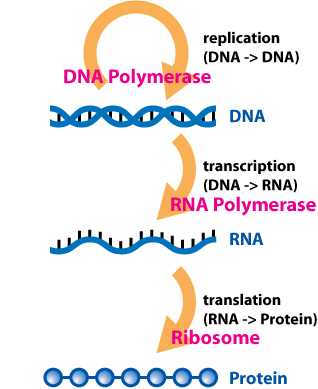
- Alexander Dounce (1952) - Comment about transcription and translation
- Watson & Crick (1953) - Comment about permutation and genetic information
- Crick (1958) - Central dogma of molecular biology
- E. Zuckerland, L. Pauling (1964) - Molecules as documents of evolutionary history
- M. Dayhoff et al. (1965) - Atlas of protein sequence and structure
- Needleman-Wunsch (1970) - Sequence alignment algorithm
- P. Hogeweg & B. Hesper (1970). First time Bioinformatics term is used
A bit of history
- Sanger sequencing technique (1977)
- GenBank and EMBL (1979-1980)
- BLAST first implementation (1990)
- First genome database (1993)
- Influenza genome sequence (1995)
- Human Genome Project - First Draft (1990-2003)
References
- La naturalesa computacional de la vida (Computational nature of life, Roderic’s Guigó presentation -in Catalan-)
- Introduction and Importance of Bioinformatics
Sequences and file formats
Alphabets
Reference: Wikipedia article
Nucleic acids
| Nucleic Acid Code | Meaning | Mnemonic |
|---|---|---|
| A | A | Adenine |
| C | C | Cytosine |
| G | G | Guanine |
| T | T | Thymine |
| U | U | Uracil |
| R | A or G | puRine |
| Y | C, T or U | pYrimidines |
| K | G, T or U | bases which are Ketones |
| M | A or C | bases with aMino groups |
| S | C or G | Strong interaction |
| W | A, T or U | Weak interaction |
| B | not A (i.e. C, G, T or U) | B comes after A |
| D | not C (i.e. A, G, T or U) | D comes after C |
| H | not G (i.e., A, C, T or U) | H comes after G |
| V | neither T nor U (i.e. A, C or G) | V comes after U |
| N | A C G T U | Nucleic acid |
| - | gap of indeterminate length |
Amino acids
| Amino Acid Code | Meaning |
|---|---|
| A | Alanine |
| B | Aspartic acid (D) or Asparagine (N) |
| C | Cysteine |
| D | Aspartic acid |
| E | Glutamic acid |
| F | Phenylalanine |
| G | Glycine |
| H | Histidine |
| I | Isoleucine |
| J | Leucine (L) or Isoleucine (I) |
| K | Lysine |
| L | Leucine |
| M | Methionine/Start codon |
| N | Asparagine |
| O | Pyrrolysine |
| P | Proline |
| Q | Glutamine |
| R | Arginine |
| S | Serine |
| T | Threonine |
| U | Selenocysteine |
| V | Valine |
| W | Tryptophan |
| Y | Tyrosine |
| Z | Glutamic acid (E) or Glutamine (Q) |
| X | any |
| * | translation stop |
| - | gap of indeterminate length |
FASTA file format
Reference: Wikipedia article
Two (three) parts
- Header - 1st line. Starting with
> - Comment - 2nd line. Starting with
;(deprecated) - Sequence - 2nd, 3rd and following lines
Example with Name in Header
>MySequence
LCLYTHIGRNIYYGSYLYSETWNTGIMLLLITMATAFMGYVLPWGQMSFWGATVITNLFSAIPYIGTNLV
EWIWGGFSVDKATLNRFFAFHFILPFTMVALAGVHLTFLHETGSNNPLGLTSDSDKIPFHPYYTIKDFLG
LLILILLLLLLALLSPDMLGDPDNHMPADPLNTPLHIKPEWYFLFAYAILRSVPNKLGGVLALFLSIVIL
GLMPFLHTSKHRSMMLRPLSQALFWTLTMDLLTLTWIGSQPVEYPYTIIGQMASILYFSIILAFLPIAGX
IENY
Example with Name and Description in Header
>MySequence My description of a protein
LCLYTHIGRNIYYGSYLYSETWNTGIMLLLITMATAFMGYVLPWGQMSFWGATVITNLFSAIPYIGTNLV
EWIWGGFSVDKATLNRFFAFHFILPFTMVALAGVHLTFLHETGSNNPLGLTSDSDKIPFHPYYTIKDFLG
LLILILLLLLLALLSPDMLGDPDNHMPADPLNTPLHIKPEWYFLFAYAILRSVPNKLGGVLALFLSIVIL
GLMPFLHTSKHRSMMLRPLSQALFWTLTMDLLTLTWIGSQPVEYPYTIIGQMASILYFSIILAFLPIAGX
IENY
Example with Accessions or Identifiers, description and organism in Header
>gi|5524211|gb|AAD44166.1| cytochrome b [Elephas maximus maximus]
LCLYTHIGRNIYYGSYLYSETWNTGIMLLLITMATAFMGYVLPWGQMSFWGATVITNLFSAIPYIGTNLV
EWIWGGFSVDKATLNRFFAFHFILPFTMVALAGVHLTFLHETGSNNPLGLTSDSDKIPFHPYYTIKDFLG
LLILILLLLLLALLSPDMLGDPDNHMPADPLNTPLHIKPEWYFLFAYAILRSVPNKLGGVLALFLSIVIL
GLMPFLHTSKHRSMMLRPLSQALFWTLTMDLLTLTWIGSQPVEYPYTIIGQMASILYFSIILAFLPIAGX
IENY
Example with Accessions or Identifiers, description and organism in Header (NCBI FASTA format)
>AAD44166.1 cytochrome b, partial (mitochondrion) [Elephas maximus maximus]
LCLYTHIGRNIYYGSYLYSETWNTGIMLLLITMATAFMGYVLPWGQMSFWGATVITNLFSAIPYIGTNLV
EWIWGGFSVDKATLNRFFAFHFILPFTMVALAGVHLTFLHETGSNNPLGLTSDSDKIPFHPYYTIKDFLG
LLILILLLLLLALLSPDMLGDPDNHMPADPLNTPLHIKPEWYFLFAYAILRSVPNKLGGVLALFLSIVIL
GLMPFLHTSKHRSMMLRPLSQALFWTLTMDLLTLTWIGSQPVEYPYTIIGQMASILYFSIILAFLPIAGX
IENY
Example with Accessions or Identifiers, description and organism in Header (UniProt Fasta Headers)
>sp|O47885|CYB_ELEMA Cytochrome b OS=Elephas maximus OX=9783 GN=MT-CYB PE=3 SV=1
MTHTRKFHPLFKIINKSFIDLPTPSNISTWWNFGSLLGACLITQILTGLFLAMHYTPDTM
TAFSSMSHICRDVNYGWIIRQLHSNGASIFFLCLYTHIGRNIYYGSYLYSETWNTGIMLL
LITMATAFMGYVLPWGQMSFWGATVITNLFSAIPYIGTNLVEWIWGGFSVDKATLNRFFA
FHFILPFTMVALAGVHLTFLHETGSNNPLGLTSDSDKIPFHPYYTIKDFLGLLILILLLL
LLALLSPDMLGDPDNYMPADPLNTPLHIKPEWYFLFAYAILRSVPNKLGGVLALFLSILI
LGLMPLLHTSKHRSMMLRPLSQVLFWTLTMDLLTLTWIGSQPVEHPYIIIGQMASILYFS
IILAFLPIAGMIENYLIK
File extensions
Despite FASTA is a text file format in the end, some file extension prefixes are used as a convention for helping to identify file content among many different files.
- Generic:
.faor.fasta - Protein:
.faa - Nucleotide:
.fna - etc.
TRIVIA: File format or type is not the same as file extension, despite the later should help to identify the former.
Files can also be compressed for helping distribution and saving space.
FASTA, as text files, they can be highly compressed. You can notice it with the following extensions: .gz, .bzip2 or .zip (among others).
.gz (Gzip) is, by far, the most common compression approach and, in many cases, it is recognized by many software applications. In most cases files can even be uncompressed and opened straight from the browser.
Sequences in lowercase or uppercase
In principle it does not matter whether letters are uppercase or lowercase. However, it is quite widespread that some programs (such as RepeatMasker) convert to lowercase some low complexity sequence regions (e.g. repeats). So, it is advisable to use uppercase by default.
NOTE:
- Hard mask: Letters are converted to “X”
- Soft mask: Letters are converted to lowercase
Related
Derived extended format used in sequencing projects: FASTQ. We will discuss this in upcoming sessions.
Tools
- FaBox. FASTA manipulation, generation and processing
NCBI resources
GenBank / GenPept format
Nucleotide example: AF132523
LOCUS AF132523 853 bp DNA linear MAM 26-JUL-2016
DEFINITION Elephas maximus maximus cytochrome b gene, partial cds;
mitochondrial gene for mitochondrial product.
ACCESSION AF132523
VERSION AF132523.1
KEYWORDS .
SOURCE mitochondrion Elephas maximus maximus
ORGANISM Elephas maximus maximus
Eukaryota; Metazoa; Chordata; Craniata; Vertebrata; Euteleostomi;
Mammalia; Eutheria; Afrotheria; Proboscidea; Elephantidae; Elephas.
REFERENCE 1 (bases 1 to 853)
AUTHORS Barriel,V., Thuet,E. and Tassy,P.
TITLE Molecular phylogeny of Elephantidae. Extreme divergence of the
extant forest African elephant
JOURNAL C. R. Acad. Sci. III, Sci. Vie 322 (6), 447-454 (1999)
PUBMED 10457597
REFERENCE 2 (bases 1 to 853)
AUTHORS Barriel,V. and Thuet,E.
TITLE Direct Submission
JOURNAL Submitted (02-MAR-1999) Service de Systematique Moleculaire, Museum
National d'Histoire Naturelle, 43 rue Cuvier, Paris 75005, France
FEATURES Location/Qualifiers
source 1..853
/organism="Elephas maximus maximus"
/organelle="mitochondrion"
/mol_type="genomic DNA"
/sub_species="maximus"
/db_xref="taxon:99488"
/country="Sri Lanka"
CDS <1..>853
/codon_start=1
/transl_table=2
/product="cytochrome b"
/protein_id="AAD44166.1"
/translation="LCLYTHIGRNIYYGSYLYSETWNTGIMLLLITMATAFMGYVLPW
GQMSFWGATVITNLFSAIPYIGTNLVEWIWGGFSVDKATLNRFFAFHFILPFTMVALA
GVHLTFLHETGSNNPLGLTSDSDKIPFHPYYTIKDFLGLLILILLLLLLALLSPDMLG
DPDNHMPADPLNTPLHIKPEWYFLFAYAILRSVPNKLGGVLALFLSIVILGLMPFLHT
SKHRSMMLRPLSQALFWTLTMDLLTLTWIGSQPVEYPYTIIGQMASILYFSIILAFLP
IAGXIENY"
ORIGIN
1 ctctgcctat acacacacat tggacgaaac atctactatg gatcctacct atactcagaa
61 acctgaaaca caggtattat actactacta atcaccatag ccaccgcctt cataggatat
121 gtccttccat gaggacaaat atcattctga ggggcaaccg taattactaa cctcttctca
181 gcaattccct acatcggcac aaacctagta gaatgaattt gaggaggctt ttcggtagat
241 aaagcaacct taaaccgatt cttcgccttc catttcatcc ttccatttac tatagttgca
301 ctagcaggag tgcacctaac ctttcttcac gaaacaggct caaacaaccc actaggtctc
361 acttcagact cagataaaat tcccttccac ccgtactata ctatcaaaga cttcctagga
421 ctacttatcc taattttact ccttctactc ttagccctac tatctccaga catactagga
481 gaccctgaca accacatacc agctgatcca ctaaataccc ccctacatat caaaccagag
541 tgatacttcc tttttgctta cgccatccta cgatctgtac caaataaact aggaggcgtc
601 ctagccctat tcctatcaat tgtgatttta ggattaatac catttctcca tacatccaag
661 caccgaagta taatactccg acctctcagc caggccctat tctgaactct aacaatagat
721 ttactaacac ttacatgaat tggcagtcaa ccagtagaat acccctacac cattattggc
781 caaatagcct caattctata cttctccatt attctagctt tcctaccaat tgcagganta
841 atcgaaaact acc
//
Protein example: AAD44166
LOCUS AAD44166 284 aa linear MAM 26-JUL-2016
DEFINITION cytochrome b, partial (mitochondrion) [Elephas maximus maximus].
ACCESSION AAD44166
VERSION AAD44166.1
DBSOURCE accession AF132523.1
KEYWORDS .
SOURCE mitochondrion Elephas maximus maximus
ORGANISM Elephas maximus maximus
Eukaryota; Metazoa; Chordata; Craniata; Vertebrata; Euteleostomi;
Mammalia; Eutheria; Afrotheria; Proboscidea; Elephantidae; Elephas.
REFERENCE 1 (residues 1 to 284)
AUTHORS Barriel,V., Thuet,E. and Tassy,P.
TITLE Molecular phylogeny of Elephantidae. Extreme divergence of the
extant forest African elephant
JOURNAL C. R. Acad. Sci. III, Sci. Vie 322 (6), 447-454 (1999)
PUBMED 10457597
REFERENCE 2 (residues 1 to 284)
AUTHORS Barriel,V. and Thuet,E.
TITLE Direct Submission
JOURNAL Submitted (02-MAR-1999) Service de Systematique Moleculaire, Museum
National d'Histoire Naturelle, 43 rue Cuvier, Paris 75005, France
COMMENT Method: conceptual translation.
FEATURES Location/Qualifiers
source 1..284
/organism="Elephas maximus maximus"
/organelle="mitochondrion"
/sub_species="maximus"
/db_xref="taxon:99488"
/country="Sri Lanka"
Protein <1..>284
/product="cytochrome b"
Region <1..115
/region_name="Cytochrome_b_N"
/note="Cytochrome b (N-terminus)/b6/petB: Cytochrome b is
a subunit of cytochrome bc1, an 11-subunit mitochondrial
respiratory enzyme. Cytochrome b spans the mitochondrial
membrane with 8 transmembrane helices (A-H) in eukaryotes.
In plants and cyanobacteria; cd00284"
/db_xref="CDD:238176"
Site order(30,33..34,37..38,51,54..55,59,87,90)
/site_type="other"
/note="Qo binding site"
/db_xref="CDD:238176"
Region 116..263
/region_name="cytochrome_b_C"
/note="Cytochrome b(C-terminus)/b6/petD: Cytochrome b is a
subunit of cytochrome bc1, an 11-subunit mitochondrial
respiratory enzyme. Cytochrome b spans the mitochondrial
membrane with 8 transmembrane helices (A-H) in eukaryotes.
In plants and cyanobacteria; cd00290"
/db_xref="CDD:238179"
Site order(116..118,120..128,131..133,135..136,139,142..143,
146,149..150,153..154,156,162,165..166,220..221,225,227)
/site_type="other"
/note="interchain domain interface [polypeptide binding]"
/db_xref="CDD:238179"
Site order(116..117,122,125..127,129,133,136..137,140..141,144,
148..149,151..153,156,161,163..164,166..170,172..174,177,
179..182,197,207,210..211,213..215,217)
/site_type="other"
/note="intrachain domain interface"
/db_xref="CDD:238179"
Site order(129,137)
/site_type="other"
/note="Qi binding site"
/db_xref="CDD:238179"
Site order(177,179..180,183,186..187,203)
/site_type="other"
/note="Qo binding site"
/db_xref="CDD:238179"
CDS 1..284
/coded_by="AF132523.1:<1..>853"
/transl_table=2
ORIGIN
1 lclythigrn iyygsylyse twntgimlll itmatafmgy vlpwgqmsfw gatvitnlfs
61 aipyigtnlv ewiwggfsvd katlnrffaf hfilpftmva lagvhltflh etgsnnplgl
121 tsdsdkipfh pyytikdflg llililllll lallspdmlg dpdnhmpadp lntplhikpe
181 wyflfayail rsvpnklggv lalflsivil glmpflhtsk hrsmmlrpls qalfwtltmd
241 lltltwigsq pveypytiig qmasilyfsi ilaflpiagx ieny
//
RefSeq
The Reference Sequence (RefSeq) collection provides a comprehensive, integrated, non-redundant, well-annotated set of sequences, including genomic DNA, transcripts, and proteins. RefSeq sequences form a foundation for medical, functional, and diversity studies. They provide a stable reference for genome annotation, gene identification and characterization, mutation and polymorphism analysis (especially RefSeqGene records), expression studies, and comparative analyses.
https://www.ncbi.nlm.nih.gov/refseq/
| Category | Description |
|---|---|
| NC | Complete genomic molecules |
| NG | Incomplete genomic region |
| NM | mRNA |
| NR | ncRNA |
| NP | Protein |
| XM | predicted mRNA model |
| XR | predicted ncRNA model |
| XP | predicted Protein model (eukaryotic sequences) |
| WP | predicted Protein model (prokaryotic sequences) |
Source: Wikipedia article
Other databases
- NCBI Taxonomy: Elephas maximus maximus
- Assemblies, BioProjects, Sequence Read Archive, etc. (list)
- Exercise: Search your favourite molecule from the global search and inspect the different matches.
- Example: carboxypeptidase
-
Exercise: Get all cytochrome mRNA entries from both mouse and rat.
- Exercise: How many exons does BRCA1 Human gene contain?
Batch Entrez
- Exercise: Get a list of IDs, submit them and check results.
My NCBI
Keeps track of all your searches, page visits. Allow creating collections to group entries of our interest, etc.
Advanced usage
Example query: ```carboxypeptidase AND rat[Organism] AND srcdb_refseq[PROP]``
- Reference: List of tags
UniProt
Consortium: European Bioinformatics Institute (EBI), the Swiss Institute of Bioinformatics (SIB) and the Protein Information Resource (PIR).
Resources
- UniProtKB
- UniProtKB/Swiss-Prot. Curated anotation
- UniProtKB/TrEMBL. Automatic annotation from EMBL
- UniParc. Comprehensive and non-redundant database from different sources (sources: ENSEMBL, RefSeq, PDB, etc.)
- UniRef. Redundancy datasets: UniRef100, UniRef90, UniRef50.
Other formats
-
Traditional SwissProt Format
-
Protein example: O47885
ID CYB_ELEMA Reviewed; 378 AA.
AC O47885; O47886; Q34481;
DT 30-MAY-2000, integrated into UniProtKB/Swiss-Prot.
DT 01-JUN-1998, sequence version 1.
DT 11-DEC-2019, entry version 90.
DE RecName: Full=Cytochrome b;
DE AltName: Full=Complex III subunit 3;
DE AltName: Full=Complex III subunit III;
DE AltName: Full=Cytochrome b-c1 complex subunit 3;
DE AltName: Full=Ubiquinol-cytochrome-c reductase complex cytochrome b subunit;
GN Name=MT-CYB; Synonyms=COB, CYTB, MTCYB;
OS Elephas maximus (Indian elephant).
OG Mitochondrion.
OC Eukaryota; Metazoa; Chordata; Craniata; Vertebrata; Euteleostomi; Mammalia;
OC Eutheria; Afrotheria; Proboscidea; Elephantidae; Elephas.
OX NCBI_TaxID=9783;
RN [1]
RP NUCLEOTIDE SEQUENCE [GENOMIC DNA].
RC TISSUE=Hair, and Muscle;
RX PubMed=9493356; DOI=10.1007/pl00006308;
RA Noro M., Masuda R., Dubrovo I.A., Yoshida M.C., Kato M.;
RT "Molecular phylogenetic inference of the woolly mammoth Mammuthus
RT primigenius, based on complete sequences of mitochondrial cytochrome b and
RT 12S ribosomal RNA genes.";
RL J. Mol. Evol. 46:314-326(1998).
RN [2]
RP NUCLEOTIDE SEQUENCE [GENOMIC DNA] OF 1-335.
RC TISSUE=Blood;
RX PubMed=9089080; DOI=10.1007/pl00006160;
RA Ozawa T., Hayashi S., Mikhelson V.M.;
RT "Phylogenetic position of mammoth and Steller's sea cow within Tethytheria
RT demonstrated by mitochondrial DNA sequences.";
RL J. Mol. Evol. 44:406-413(1997).
RN [3]
RP NUCLEOTIDE SEQUENCE [GENOMIC DNA] OF 32-106.
RX PubMed=8577738; DOI=10.1073/pnas.93.3.1190;
RA Yang H., Golenberg E.M., Shoshani J.;
RT "Phylogenetic resolution within the Elephantidae using fossil DNA sequence
RT from the American mastodon (Mammut americanum) as an outgroup.";
RL Proc. Natl. Acad. Sci. U.S.A. 93:1190-1194(1996).
CC -!- FUNCTION: Component of the ubiquinol-cytochrome c reductase complex
CC (complex III or cytochrome b-c1 complex) that is part of the
CC mitochondrial respiratory chain. The b-c1 complex mediates electron
CC transfer from ubiquinol to cytochrome c. Contributes to the generation
CC of a proton gradient across the mitochondrial membrane that is then
CC used for ATP synthesis. {ECO:0000250|UniProtKB:P00157}.
CC -!- COFACTOR:
CC Name=heme; Xref=ChEBI:CHEBI:30413;
CC Evidence={ECO:0000250|UniProtKB:P00157};
CC Note=Binds 2 heme groups non-covalently.
CC {ECO:0000250|UniProtKB:P00157};
CC -!- SUBUNIT: The cytochrome bc1 complex contains 11 subunits: 3 respiratory
CC subunits (MT-CYB, CYC1 and UQCRFS1), 2 core proteins (UQCRC1 and
CC UQCRC2) and 6 low-molecular weight proteins (UQCRH/QCR6, UQCRB/QCR7,
CC UQCRQ/QCR8, UQCR10/QCR9, UQCR11/QCR10 and a cleavage product of
CC UQCRFS1). This cytochrome bc1 complex then forms a dimer.
CC {ECO:0000250|UniProtKB:P00157}.
CC -!- SUBCELLULAR LOCATION: Mitochondrion inner membrane
CC {ECO:0000250|UniProtKB:P00157}; Multi-pass membrane protein
CC {ECO:0000250|UniProtKB:P00157}.
CC -!- MISCELLANEOUS: Heme 1 (or BL or b562) is low-potential and absorbs at
CC about 562 nm, and heme 2 (or BH or b566) is high-potential and absorbs
CC at about 566 nm. {ECO:0000250}.
CC -!- SIMILARITY: Belongs to the cytochrome b family. {ECO:0000255|PROSITE-
CC ProRule:PRU00967, ECO:0000255|PROSITE-ProRule:PRU00968}.
CC -!- CAUTION: The full-length protein contains only eight transmembrane
CC helices, not nine as predicted by bioinformatics tools.
CC {ECO:0000250|UniProtKB:P00157}.
CC ---------------------------------------------------------------------------
CC Copyrighted by the UniProt Consortium, see https://www.uniprot.org/terms
CC Distributed under the Creative Commons Attribution (CC BY 4.0) License
CC ---------------------------------------------------------------------------
DR EMBL; D50844; BAA25009.1; -; Genomic_DNA.
DR EMBL; D50846; BAA25010.1; -; Genomic_DNA.
DR EMBL; AB002412; BAA25017.1; -; Genomic_DNA.
DR EMBL; D83048; BAA20278.1; -; Genomic_DNA.
DR EMBL; U23740; AAA73783.1; -; Genomic_DNA.
DR SMR; O47885; -.
DR GO; GO:0016021; C:integral component of membrane; IEA:UniProtKB-KW.
DR GO; GO:0005743; C:mitochondrial inner membrane; IEA:UniProtKB-SubCell.
DR GO; GO:0045275; C:respiratory chain complex III; IEA:InterPro.
DR GO; GO:0046872; F:metal ion binding; IEA:UniProtKB-KW.
DR GO; GO:0008121; F:ubiquinol-cytochrome-c reductase activity; IEA:InterPro.
DR GO; GO:0006122; P:mitochondrial electron transport, ubiquinol to cytochrome c; IEA:InterPro.
DR CDD; cd00290; cytochrome_b_C; 1.
DR CDD; cd00284; Cytochrome_b_N; 1.
DR Gene3D; 1.20.810.10; -; 1.
DR InterPro; IPR005798; Cyt_b/b6_C.
DR InterPro; IPR036150; Cyt_b/b6_C_sf.
DR InterPro; IPR005797; Cyt_b/b6_N.
DR InterPro; IPR027387; Cytb/b6-like_sf.
DR InterPro; IPR030689; Cytochrome_b.
DR InterPro; IPR016174; Di-haem_cyt_TM.
DR Pfam; PF00032; Cytochrom_B_C; 1.
DR Pfam; PF00033; Cytochrome_B; 1.
DR PIRSF; PIRSF038885; COB; 1.
DR SUPFAM; SSF81342; SSF81342; 1.
DR SUPFAM; SSF81648; SSF81648; 1.
DR PROSITE; PS51003; CYTB_CTER; 1.
DR PROSITE; PS51002; CYTB_NTER; 1.
PE 3: Inferred from homology;
KW Electron transport; Heme; Iron; Membrane; Metal-binding; Mitochondrion;
KW Mitochondrion inner membrane; Respiratory chain; Transmembrane;
KW Transmembrane helix; Transport; Ubiquinone.
FT CHAIN 1..378
FT /note="Cytochrome b"
FT /id="PRO_0000060911"
FT TRANSMEM 33..53
FT /note="Helical"
FT /evidence="ECO:0000250|UniProtKB:P00157"
FT TRANSMEM 77..98
FT /note="Helical"
FT /evidence="ECO:0000250|UniProtKB:P00157"
FT TRANSMEM 113..133
FT /note="Helical"
FT /evidence="ECO:0000250|UniProtKB:P00157"
FT TRANSMEM 178..198
FT /note="Helical"
FT /evidence="ECO:0000250|UniProtKB:P00157"
FT TRANSMEM 226..246
FT /note="Helical"
FT /evidence="ECO:0000250|UniProtKB:P00157"
FT TRANSMEM 288..308
FT /note="Helical"
FT /evidence="ECO:0000250|UniProtKB:P00157"
FT TRANSMEM 320..340
FT /note="Helical"
FT /evidence="ECO:0000250|UniProtKB:P00157"
FT TRANSMEM 347..367
FT /note="Helical"
FT /evidence="ECO:0000250|UniProtKB:P00157"
FT METAL 83
FT /note="Iron 1 (heme b562 axial ligand)"
FT /evidence="ECO:0000250|UniProtKB:P00157"
FT METAL 97
FT /note="Iron 2 (heme b566 axial ligand)"
FT /evidence="ECO:0000250|UniProtKB:P00157"
FT METAL 182
FT /note="Iron 1 (heme b562 axial ligand)"
FT /evidence="ECO:0000250|UniProtKB:P00157"
FT METAL 196
FT /note="Iron 2 (heme b566 axial ligand)"
FT /evidence="ECO:0000250|UniProtKB:P00157"
FT BINDING 201
FT /note="Ubiquinone"
FT /evidence="ECO:0000250|UniProtKB:P00157"
FT VARIANT 7
FT /note="F -> S"
FT VARIANT 306
FT /note="L -> F"
FT VARIANT 345
FT /note="H -> Y"
FT VARIANT 348
FT /note="I -> T"
SQ SEQUENCE 378 AA; 42882 MW; 5A5FDF7BE9D15333 CRC64;
MTHTRKFHPL FKIINKSFID LPTPSNISTW WNFGSLLGAC LITQILTGLF LAMHYTPDTM
TAFSSMSHIC RDVNYGWIIR QLHSNGASIF FLCLYTHIGR NIYYGSYLYS ETWNTGIMLL
LITMATAFMG YVLPWGQMSF WGATVITNLF SAIPYIGTNL VEWIWGGFSV DKATLNRFFA
FHFILPFTMV ALAGVHLTFL HETGSNNPLG LTSDSDKIPF HPYYTIKDFL GLLILILLLL
LLALLSPDML GDPDNYMPAD PLNTPLHIKP EWYFLFAYAI LRSVPNKLGG VLALFLSILI
LGLMPLLHTS KHRSMMLRPL SQVLFWTLTM DLLTLTWIGS QPVEHPYIII GQMASILYFS
IILAFLPIAG MIENYLIK
//
Notice ID and AC lines
AC is recommended as more stable. Manual
Additional features
- Post-translational modifications (PTMs)
- interaction
- Structural information
- Functional information (GOs)
- etc.
Isoforms
Some entries may have isoforms. Example: P04150, P04150-2, P04150-3, etc. Reference
- Exercise: For
BRCA1_HUMANwhat is the length of the shortest known isoform?
Search capabilities
Example query: carboxypeptidase AND reviewed:yes AND organism:"Rattus norvegicus (Rat) [10116]"
- Exercise: Get all cytochrome unreviewed (TrEMBL) protein entries from both mouse and rat.
ID mapping
-
Exercise: Input different UniProt protein cytochrome entries and retrieve correspondent RefSeq IDs.
Other resources
Other tools
- EMBOSS Seqret Conversion of formats
- Exercise: Convert some of the non-FASTA format entries above to FASTA
- Exercise: Translate the amino acid sequence of the shortest isoform of
BRCA1_HUMANprotein to nucleotide sequence.