

Mapping using Salmon
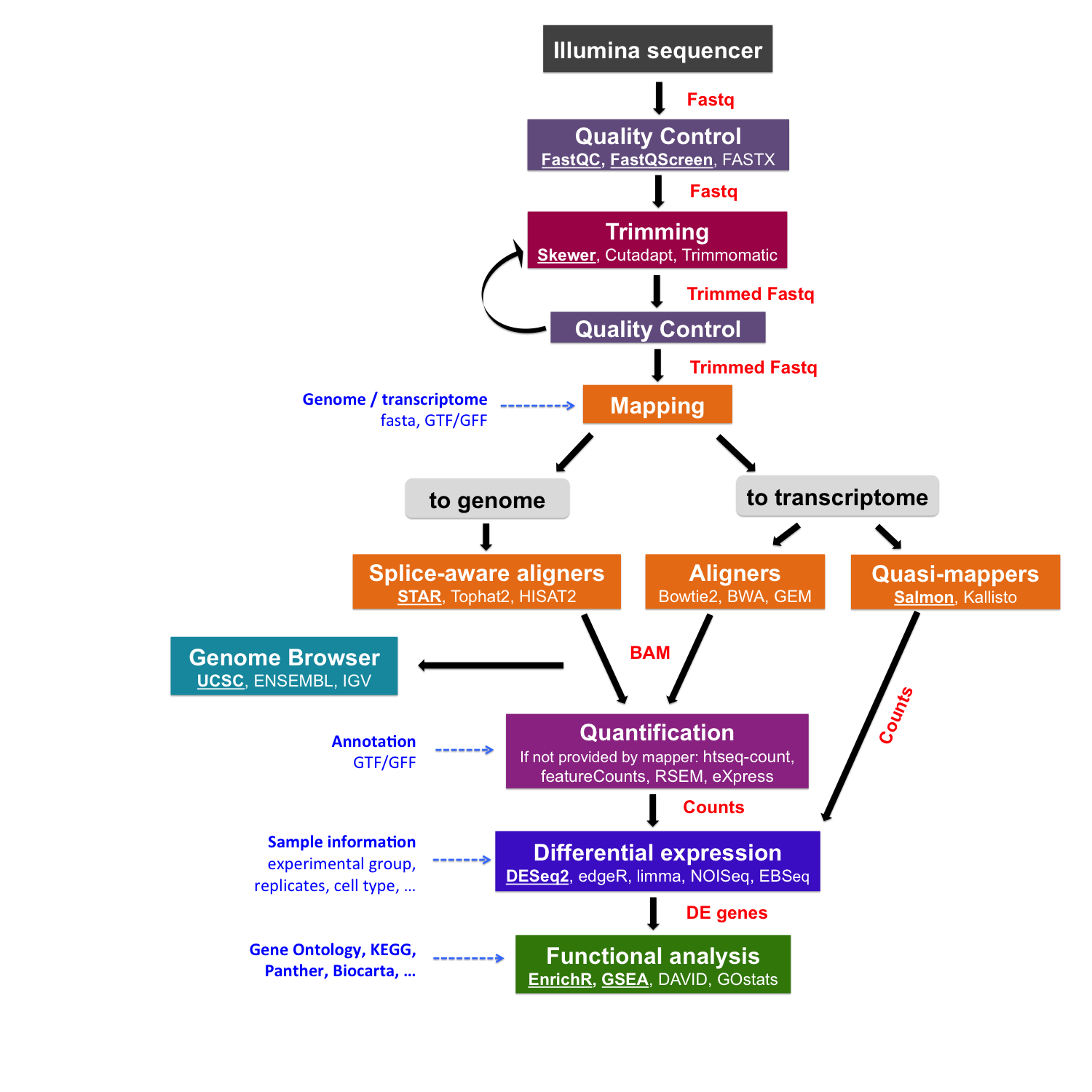
Salmon is a tool for quantifying the expression of transcripts using RNA-seq data.
It is a quasi-mapper: it doesn’t produce the read alignments (and doesn’t output BAM/SAM files). Salmon “quasi-maps” reads to the transcriptome rather than to the genome.
Salmon can also make use of pre-computed alignments (in the form of a SAM/BAM file) instead of the FASTQ files.
Building the Salmon index
To make an index for Salmon, we need transcript sequences in the FASTA format.
This can be found easily in GENCODE.
The transcript sequences corresponding to chromosome 6 was prepared and already downloaded in ~/rnaseq_course/reference_genome/
Salmon does not need any decompression of the input, so we can index by using this command:
cd ~/rnaseq_course/mapping
# index and store the index files in index_salmon folder
$RUN salmon index -t ~/rnaseq_course/reference_genome/reference_chr6/gencode.v33.transcripts.chr6.fa.gz \
-i index_salmon \
--gencode
We add the parameter –gencode as our data come from Gencode version 33 and their header contains several identifiers separated by the character |. This parameter allows the program to parse the header and keep only the transcript identifier.
Quantifying transcript expression
To quantify reads with Salmon, we need to specify the type sequencing library, aka Fragment Library Types in Salmon, using three letters:
The first:
| Symbol | Meaning | Reads |
|---|---|---|
| I | inward | -> … <- |
| O | outward | <- … -> |
| M | matching | -> … -> |
The second:
| Symbol | Meaning |
|---|---|
| S | stranded |
| U | unstranded |
The third:
| Symbol | Meaning |
|---|---|
| F | read 1 (or single-end read) comes from the forward strand |
| R | read 1 (or single-end read) comes from the reverse strand |
From the STAR output for read counts we already know that for the analyzed experiment the U (Unstranded) library was used.
If the library was paired-end and sequenced with a stranded reverse library, we would set the parameter to ISR.
If we want to assign the reads to the genes (option -g) in addition to transcripts we have to provide a GTF file corresponding to the transcript version which was used to build the Salmon index.
We have it already for chromosome 6, in ~/rnaseq_course/reference_genome/
We can proceed with the mapping.
cd ~/rnaseq_course/mapping
# create folder for salmon's output files
mkdir alignments_salmon
$RUN salmon quant -i index_salmon -l U \
-r ~/rnaseq_course/raw_data/fastq_chr6/SRR3091420_1_chr6.fastq.gz \
-o alignments_salmon/SRR3091420_1_chr6_salmon \
-g ~/rnaseq_course/reference_genome/reference_chr6/gencode.v33.annotation_chr6.gtf.gz \
--seqBias \
--validateMappings
We can check the results inside the folder “alignments”.
ls alignments_salmon/SRR3091420_1_chr6_salmon/
For explanation of all output files, see the Salmon documentation.
The most interesting to us in this course is the file quant.genes.sf, that is a tab-separated file containing the read counts for genes:
| Column | Meaning |
|---|---|
| Name | Gene name |
| Length | Gene length |
| EffectiveLength | Effective length after considering biases |
| TPM | Transcripts Per Million |
| NumReads | Estimated number of reads considering both univocally and multimapping reads |
head -n 5 alignments_salmon/SRR3091420_1_chr6_salmon/quant.genes.sf
Name Length EffectiveLength TPM NumReads
ENSG00000285803.1 1152 1116.21 7.96961 15.764
ENSG00000285712.1 1590 1545.58 2.19064 6
ENSG00000285824.1 1120 860.855 6.91601 10.551
ENSG00000285884.1 790 515.683 3.28285 3
There is a similarly formatted file quant.sf that provides read counts for transcript:
head -n 5 alignments_salmon/SRR3091420_1_chr6_salmon/quant.sf
Name Length EffectiveLength TPM NumReads
ENST00000016171.5 2356 1970.742 659.861626 2304.468
ENST00000020673.5 4183 5925.497 0.000000 0.000
ENST00000173785.4 925 868.802 0.000000 0.000
ENST00000181796.6 3785 3216.057 0.000000 0.000
We will use information on read counts for genes from quant.sf files for the differential expression (DE) analysis.
Now if time and resources allows, proceed with the mapping of the 9 remaining samples:
cd ~/rnaseq_course/mapping
for fastq in ~/rnaseq_course/raw_data/fastq_chr6/SRR309142{1,2,3,4,5,6,7,8,9}_1_chr6.fastq.gz
do echo $fastq
$RUN salmon quant -i index_salmon -l U \
-r ${fastq} \
-o alignments_salmon/$(basename $fastq .fastq.gz)_salmon \
-g ~/rnaseq_course/reference_genome/reference_chr6/gencode.v33.annotation_chr6.gtf.gz \
--seqBias \
--validateMappings
done